In a world of rapidly evolving technologies, ensuring user satisfaction is paramount. It doesn't matter what the microprocessor is doing in the background; what counts is that the solution works, is reliable, and is scalable. DevOps, MLOps, and LLMOps are not just technical concepts: they ensure that software and AI models remain relevant and performant over time. But how do they differ, and why are they essential? Let's break it down.
Why DevOps, MLOps & LLMOps?
The lifecycle of a piece of software does not end at its release to production. Of course, software will have passed all the development stages and successfully completed the qualification phase, which is arguably the most crucial.
However, this validation phase with selected users, even if hoped to be as representative as possible, is rarely entirely faithful to its long-term use: there will always be a user who performs an unexpected action, highlighting a weakness in the software… to be corrected. And, as it should be, time will do its work: the activity will evolve and the software will have to follow this transformation.
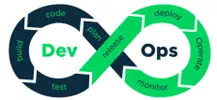
This acceptance of the need to continuously evolve a solution has led to the implementation of DevOps solutions, a contraction of «Development» and «Operations». Often represented by a figure-of-eight loop, the principle is to automate the software lifecycle in a repeatable and reliable manner.
And so, the software will follow a full cycle of automated transformations: from compilation, to testing, to deployment, to user feedback... back to the developer. The aim of DevOps is to ensure the best possible level of solution maintenance through a controlled approach, regardless of how it was achieved.
More recently, this notion has today been extended to MLOps (Machine Learning – Ops) and LLMOps (Large Language Model – Ops). It is appropriate to speak of «variants» because artificial intelligence projects remain, first and foremost, IT projects, even if the latter bring specificities that need to be addressed.
«Classic» software development»
In the case of classic software development, with a programme in Java, Python, or any other programming language, it is this source code that must be maintained.
An essential dimension of this process is that the source code can evolve without jeopardising validated functionalities. Naturally, one thinks of anomaly corrections («bugs»), but it can also be more fundamental corrections requiring potential restructuring of the programme («refactoring»). These changes allow for improvements in code performance and readability without impacting the user experience.
What matters here is that The software runs smoothly and reliably, regardless of the technical adjustments hidden beneath the surface: only the result counts, but it is the source code that is at stake.
MLOps Developments
The development of an AI project« Classic »(MLOps) goes through several basic stages:
- Acquisition, cleaning, and preparation of data, often using «pipelines» that chain together elementary operations.
- Development of algorithms, often through «Notebooks». These somewhat peculiar editors, frequently used by Data Scientists, allow for the testing of algorithms without going through a complete development procedure, even though the code must be adapted to achieve deployable quality.
These different stages must, like any production, go through version management and testing mechanisms, particularly for pipelines.
However, the deployment of code is not the end of the AI application's evolution. Indeed, in classic AI, models are trained based on examples, a dataset that is sought to be as close to reality as possible. But the world changes. So does «reality». As a result, data that was thought to be representative may no longer be so and the model loses its relevance. It then becomes necessary to measure a potential drift of the models or the data (this is referred to as « Data Drift » and « Model drift »).
In fact, if the code is at the heart of the DevOps approach, these are indeed the data and the model What are the sensitive points of an MLOps project. A high-performing model today can be obsolete tomorrow if the input data changes. The MLOps therefore aims to automate the monitoring, adaptation and continuous improvement of models so that they remain relevant and effective.
Here, the most valuable asset is the data and the model derived from it.
LLMOps Development
LLMOps development, as the name suggests, relies on LLMs. These foundational models are now plentiful, each claiming to be better than the rest. In fact, while quality is constantly improving, ultimately, these models remain statistical, stochastic, and therefore imperfect in a non-deterministic sense.
Furthermore, as model updates are happening almost weekly rather than monthly, what will count is the use and control that will be made of it rather than the intrinsic quality of that which is chosen.
In other words, what will create value: This is the prompt. The way it is formulated, the precision with which questions are asked will have a great influence on the result obtained. Today, the management and optimisation of prompts are becoming a critical element, on the same level as model training in MLOps. LLMOps therefore consists of to structure and monitor the use of language models to ensure consistent and reliable results.
Ultimately, here, the essential part that matters and will matter most tomorrow is the prompt. It is this that becomes the essential element of LLMOps.
Conclusion
The object of IT development is not to write a programme, but rather to Provide a solution that meets user needs and evolves with their expectations.
Binary code executed by processors has long ceased to be of interest, as it is regenerated with each iteration. DevOps methods, which govern software lifecycles, have effectively moved up a level of abstraction.
With MLOps, this ascent continues. Here, data and model monitoring are becoming the key elements to ensure the relevance and performance of AI solutions. Today, the generation of a solution increasingly relies on intelligently designed prompts. LLMOps thus focuses on mastering the interaction with language models., ensuring the generated results remain consistent and actionable.
What really matters is not the underlying architecture, but user experience, relevance of responses, and the ability to evolve with market needs.
To learn how to integrate these solutions effectively: