Large Language Models (LLMs) offer fascinating prospects, but their reliability remains a crucial challenge. At JEMS, we explore techniques to limit the risks associated with «hallucinations», in order to ensure relevant and robust results in critical contexts. Discover our methodology and the solutions we favour.
A weakness by design
LLMs are statistical machines. They predict and generate the next word to be emitted based on the probability linked to the context provided to them, that is, the preceding words. The results produced since 2022 are undoubtedly spectacular, as are the «failures» which are sometimes known as «hallucinations». The fact that a word is «probable» does not mean it is «correct».
The risks of hallucinations
While these hallucinations may prove «acceptable» in the context of creative or imaginative work, where they can allow for the consideration of aspects one might not otherwise think of, they can be disastrous in cases where the quality of the output is important. For example:
- Response to a client regarding a specific point in the contract. Incidents of damage to company image are on the rise;
- How an Agent may make the wrong decision, failing to invoke the correct tool, which can significantly harm its performance.
The works
The simplest technique to avoid these drawbacks is to set the «temperature» to zero. This parameter actually represents the statistical representation at the output of the neural network. The higher the «temperature», the closer the statistical weights of the candidate words become, and therefore the more the text can go in one direction or another.
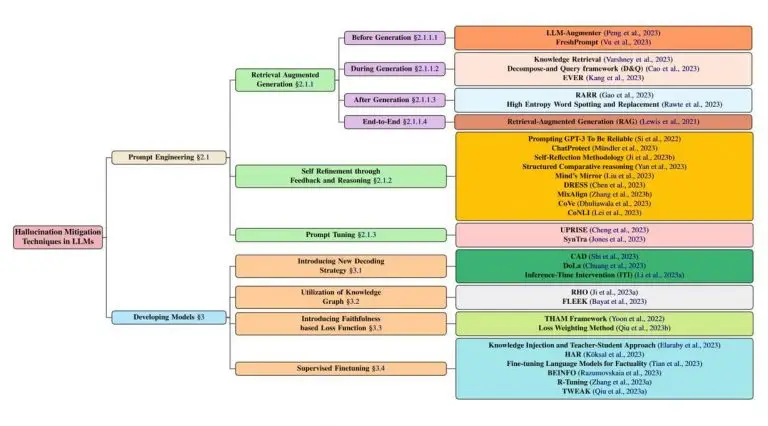
Unfortunately, playing with this single setting will not be enough and it will be necessary to find other solutions to control the production of LLMs. Many scientific articles have been written on this subject, and a synthesis is available here (https://arxiv.org/html/2401.01313v2). The authors distinguish between two main categories of methods:
- Prompt-related approaches, which optimise the formulation of questions posed to the model.
- Model adjustments, involving structural modifications or specific training.
From our point of view, model-based methods are both:
- Exposed to the same risks.
They are more complex, as in most cases they require a training base. Whether in the classic form of questions/answers (often used in these fine-tuning cases) or by relying on the very structure of the models:
- Modification of output probabilities («Context-Aware-Decoding», «Decoding by Contrasting Layers»)
- Application of «Attention» techniques to keep generation focused on important parameters
They are subject to the same risks, because ultimately, there is no control over the generation, which is always statistical, in the output.
The other techniques presented in the study mentioned follow a different approach, focusing on the question and the information provided. The LLM is not being questioned here, which offers two advantages:
- The proposed solutions are adaptable to any type of LLM.
- Are not subject to version evolution and regular model updates that would require taking the previous work into account.
In fact, these techniques rely on «off-the-shelf» solutions and instead seek to «frame» and «control» the production of an LLM, even if it means revising them.
Techniques for governing the production of LLMs
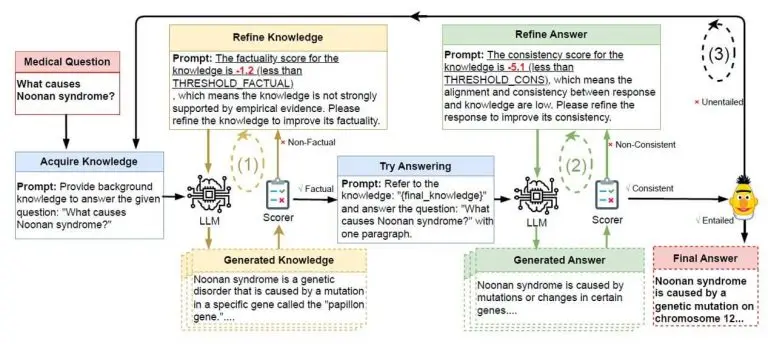
At its core, we'll find «Guardrails»-type mechanics. This involves having a feedback loop (a bit like servomechanisms), that is to say, a mechanism controlling production relative to expectations. As long as the quality does not reach the expected level, the LLM is prompted to regenerate a new response.
Several methods designated as self-refinement through feedback and reasoning are mentioned in the article. These include:
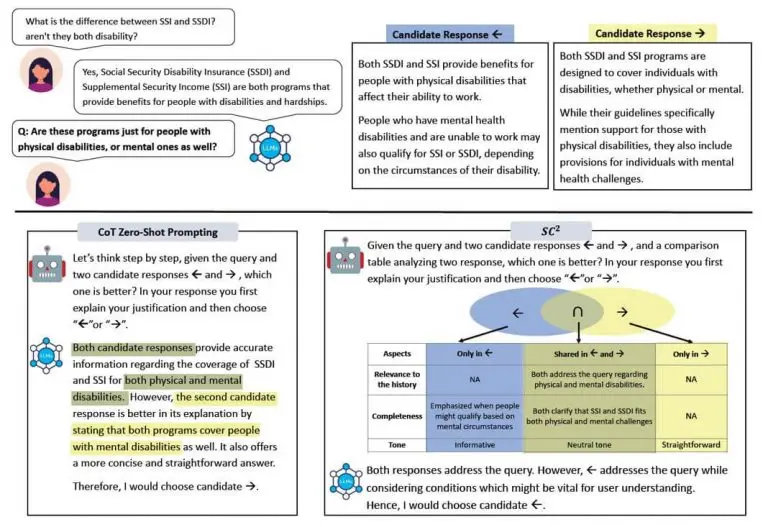
- Chat-Protect: this method aims to highlight contradictions and inconsistencies in reasoning.
- Self-Reflection: Gradual integration of data into reflection
- Structured Comparative Reasoning: the method produces different intermediate results and seeks to retain the most relevant outcome. By operating in stages, the result leads to greater coherence and completeness.
This last method is also reminiscent of the «Chain Of Verification» (CoVe), which aims to self-verify its own generations by generating questions and answering them. Similarly, CoNLI (Chain of Natural Language Inference) «self-critiques» its answers against the upstream information provided.
In general terms, one can think of reflexive, that is, prompting the LLM to check its own answers against the provided documents and the question asked. As a human, this is akin to proofreading what you've written before sending it!
Prompt-based methods or output management offer significant advantages in terms of flexibility, stability, or even simplicity compared to direct adjustments of LLMs. These approaches allow us to propose robust, adaptable, and accessible solutions, without depending on the technical complexity of the models themselves.
Conclusion
Hallucinations are therefore part of the inherent risks of LLMs. While in creative fields, this can prove to be an advantage, there are unfortunately other areas where this can become unacceptable. Several techniques are available, and from JEMS's perspective, it is preferable to favour those that are independent of LLMs and aim at error correction, rather than hoping for a «perfect» LLM.
However, one common point should be noted:
- Control the production of LLMs by breaking down a task into sub-tasks, small steps.
A hallucination, a divergence will be weaker over a short distance than a long one.
- At each stage, «self-challenge» what has been generated, if possible with a fact-checking approach, but in any case by taking a contradictory approach to verify the relevance of what is produced.
Our approach is based on the idea that mastering AI requires a structured methodology, integrating solutions tailored to each business context. By working with our clients, we develop tools that maximise the opportunities offered by AI while reducing uncertainties.
And how do you frame your AI projects to ensure reliable and relevant outcomes? Our experts are here to guide you through this transformation.