Companies have never had so much data. Yet, professions still struggle to exploit it.
For several years, organisations have been investing heavily in data platforms, governance tools, and data catalogues. The objective is clear: to structure information assets, improve data quality, and facilitate their large-scale reuse.
On paper, the promise is appealing. Employees should be able to easily find a piece of data, understand its meaning, identify its source, and use it with confidence.
In reality, few companies achieve this level of maturity.
The same difficulties often crop up:
- poorly maintained metadata,
- a strong dependence on a few experts,
- catalogues perceived as too technical,
- and above all, limited use by the trades.
Result: teams continue to manually solicit data experts, recreate their own definitions, or waste considerable time searching for information that is already available within the company.
The problem is therefore no longer solely technological. It is becoming organisational and operational.
And with the advent of generative AI usage within businesses, this limitation becomes even more apparent: an AI cannot produce reliable answers if business knowledge remains inaccessible or poorly structured.
Why are data catalogues still underutilised by business departments?
Most data catalogue projects rarely fail because of the tool itself.
Marketplace platforms are now capable of managing technical metadata, lineage, documentation, or even sensitive data classifications. However, despite these investments, business uses often remain limited.
The problem lies elsewhere: in the actual ability of departments to exploit this information. In many organisations, the catalogue is gradually becoming a tool reserved for data teams. The departments, for their part, continue to operate outside the system.
Because the “entry ticket” remains too high.
A business manager isn't looking for a technical table or a database structure. They're looking for a simple answer:
“What is the official definition of this indicator?”
“Which data is reliable for my reporting?”
“Why are two tables displaying different figures?”
However, current systems still require understanding data vocabulary, navigating complex interfaces, or knowing the technical organisation of data.
This friction creates a well-known phenomenon in large companies: expert dependency.
Certains individus deviennent les seuls points d'accès capables d'expliquer les définitions métier, les usages historiques, les règles de calcul ou les liens entre systèmes.
Over time, these experts become bottlenecks.
In some groups, teams spend several hours a week simply answering comprehension questions or manually validating metadata.
The cost is rarely measured precisely. Yet, it is considerable: project delays, loss of productivity, poor adoption of tools, multiplication of conflicting definitions and difficulty in industrialising AI use.
The most frequent limitations of data catalogues
| Observed problem | Business consequence |
|---|
| Incomplete metadata | Difficulty in understanding the data |
| Dependence on experts | High waiting times |
| Interfaces too technical | Low business adoption |
| Unmaintained documentation | Loss of confidence |
| Lack of business lineage | Difficulty reusing data |
The real subject: making data understandable without technical expertise
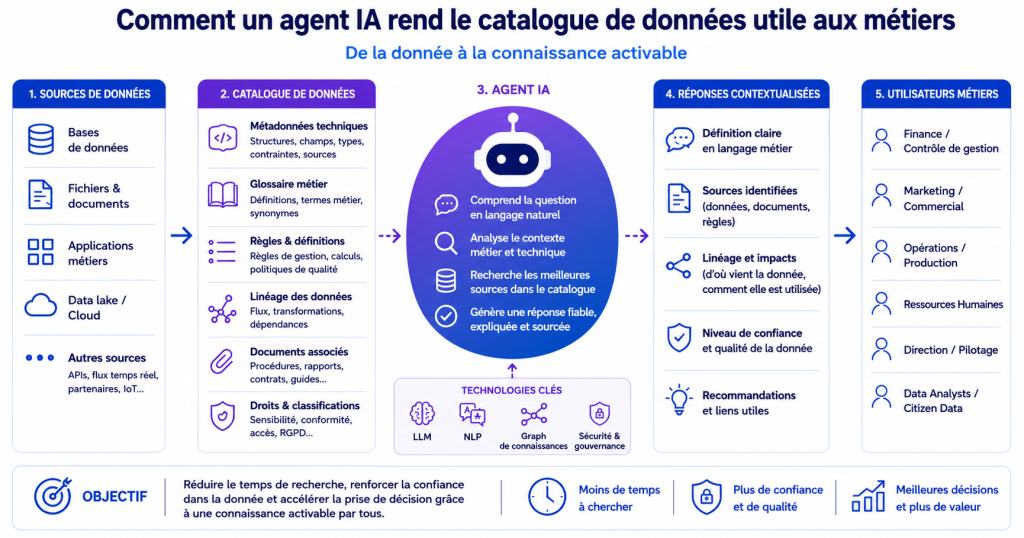
Data democratisation no longer depends solely on the quality of platforms. It now depends on users' ability to interact naturally with a company's information assets. This is precisely what generative AI use cases are set to transform.
Colleagues have become accustomed to interacting with natural language systems. They no longer want to search for information within a complex hierarchy or navigate hundreds of technical fields. They want to ask a simple question and receive a contextualised answer. This evolution is profoundly changing the role of data catalogues.
The catalogue can no longer be solely a documentary repository. It must become a system capable of linking:
Lineage becomes a key element here.
For a long time, lineage has been primarily used by technical teams to track data transformation flows. Today, it is taking on a much more strategic business dimension.
An end-user should be able to understand where does a piece of data come from, how it was transformed, Which indicators use it, quelles règles métier sont associées à celui-ci, and what level of trust to place in it. Without this understanding, the uses of AI remain fragile.
An AI can generate a response quickly. But if it relies on contradictory definitions, incomplete metadata, or outdated documentation, it primarily accelerates the spread of errors.
It is for this reason that many companies are beginning to reposition their governance projects not as compliance projects, but as necessary foundations for the industrialisation of AI.
How to make a data catalogue truly actionable?
Successful data governance organisations typically adopt a different approach. They no longer solely focus on documenting data; instead, they aim to simplify its business exploitation. This involves several important developments.
Automatically link technical and business aspects
One of the main hindrances at present remains the separation between technical metadata and business definitions. When these two worlds remain isolated, users do not truly understand what they are manipulating.
The most advanced organisations are now looking to create automatic links between technical tables, business indicators, associated documents, calculation rules, and operational uses.
Reduce reliance on experts
A governance project cannot be sustainably based on a few individuals capable of “translating” data. The objective therefore becomes to gradually embed business knowledge into systems capable of presenting it simply. AI agents are opening a new chapter here.
They enable a static catalogue to be transformed into a conversational interface capable of explaining data, locating a metric, providing context for a definition, or directing a user to the right source of information. The catalogue then becomes much more accessible to business users.
Think usage before documentation
Many projects fail because they begin with an exhaustive logic: document everything, classify everything, govern everything. This approach often results in long, complex, and difficult-to-maintain projects.
The most effective approaches generally begin with priority uses: critical reporting, strategic indicators, compliance, generative AI, operational support, or business onboarding. Governance then becomes a performance lever rather than a documentary constraint.
Evolution of the data catalogue's role
Traditional approach | AI-augmented new approach |
Technical documentation | Conversational experience |
Static reference frame | Living and contextualised system |
Expert usage | Exploitation by trades |
Keyword search | Questions in natural language |
Document governance | Usage-oriented governance |
Towards truly actionable data governance
LBusinesses have long considered data catalogues as technical repositories. With generative AI, they are gradually becoming knowledge access systems. This evolution is profoundly changing the expectations of business departments. Users no longer want to simply document data. They want to understand, query, and simply exploit the company's information assets.
At JEMS, we support organisations with this transformation by designing systems capable of connecting governance, documentary heritage, and business data exploitation through AI.
The aim is not to replace existing tools, but to finally make them accessible, reliable, and useful on a large scale, thanks to a new conversational experience around business data and knowledge.
To go further, also discover the DataKnowledge AI approach developed by JEMS around the intelligent exploitation of business knowledge: