Les entreprises n’ont jamais eu autant de données. Pourtant, les métiers peinent encore à les exploiter.
Depuis plusieurs années, les organisations investissent massivement dans des plateformes data, des outils de gouvernance et des catalogues de données. L’objectif est clair : structurer le patrimoine informationnel, améliorer la qualité des données et faciliter leur réutilisation à grande échelle.
Sur le papier, la promesse est séduisante. Un collaborateur devrait pouvoir retrouver facilement une donnée, comprendre sa signification, identifier sa source et l’utiliser en confiance.
Dans la réalité, peu d’entreprises atteignent ce niveau de maturité.
Les mêmes difficultés reviennent souvent :
- des glossaires incomplets,
- des métadonnées peu maintenues,
- une dépendance forte à quelques experts,
- des catalogues perçus comme trop techniques,
- et surtout, un faible usage par les métiers.
Résultat : les équipes continuent à solliciter manuellement les experts data, recréent leurs propres définitions ou perdent un temps considérable à chercher une information pourtant déjà disponible dans l’entreprise.
Le problème n’est donc plus uniquement technologique. Il devient organisationnel et opérationnel.
Et avec l’arrivée des usages d’IA générative dans les entreprises, cette limite devient encore plus visible : une IA ne peut pas produire des réponses fiables si la connaissance métier reste inaccessible ou mal structurée.
Pourquoi les catalogues de données restent peu utilisés par les métiers ?
La plupart des projets de catalogue de données échouent rarement à cause de l’outil lui-même.
Les plateformes du marché sont aujourd’hui capables de gérer les métadonnées techniques, le linéage, la documentation ou encore les classifications de données sensibles. Pourtant, malgré ces investissements, les usages métiers restent souvent limités.
Le problème se situe ailleurs : dans la capacité réelle des métiers à exploiter ces informations. Dans beaucoup d’organisations, le catalogue devient progressivement un outil réservé aux équipes data. Les métiers, eux, continuent à fonctionner en dehors du système.
Pourquoi ? Parce que le “ticket d’entrée” reste trop élevé.
Un responsable métier ne cherche pas une table technique ou une structure de base de données. Il cherche une réponse simple :
“Quelle est la définition officielle de cet indicateur ?”
“Quelle donnée est fiable pour mon reporting ?”
“Pourquoi deux tableaux affichent-ils des chiffres différents ?”
Or, les systèmes actuels demandent encore de comprendre le vocabulaire data, de naviguer dans des interfaces complexes ou de connaître l’organisation technique des données.
Cette friction crée un phénomène bien connu dans les grandes entreprises : la dépendance aux experts.
Quelques personnes deviennent les seuls points d’entrée capables d’expliquer les définitions métier, les usages historiques, les règles de calcul ou les liens entre systèmes.
Avec le temps, ces experts deviennent des goulots d’étranglement.
Dans certains groupes, des équipes passent plusieurs heures par semaine simplement à répondre à des questions de compréhension ou à valider manuellement des métadonnées.
Le coût est rarement mesuré précisément. Pourtant, il est considérable : ralentissement des projets, perte de productivité, faible adoption des outils, multiplication des définitions contradictoires et difficulté à industrialiser les usages IA.
Les limites les plus fréquentes des catalogues de données
| Problème observé | Conséquence métier |
|---|
| Métadonnées incomplètes | Difficulté à comprendre les données |
| Dépendance aux experts | Temps d’attente élevé |
| Interfaces trop techniques | Faible adoption métier |
| Documentation non maintenue | Perte de confiance |
| Absence de linéage métier | Difficulté à réutiliser les données |
Le vrai sujet : rendre la donnée compréhensible sans expertise technique
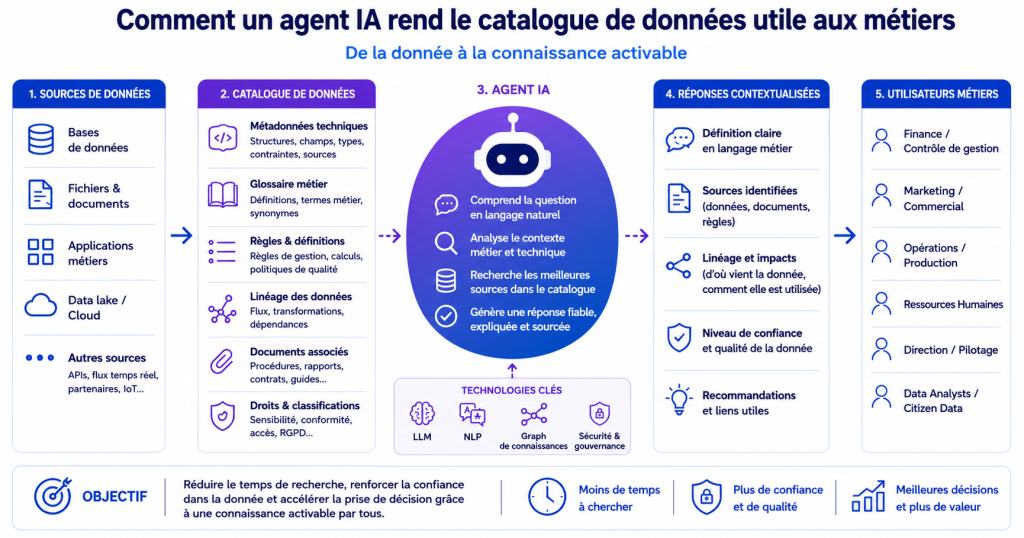
La démocratisation de la donnée ne dépend plus uniquement de la qualité des plateformes. Elle dépend désormais de la capacité des utilisateurs à dialoguer naturellement avec le patrimoine informationnel de l’entreprise. C’est précisément ce que les usages d’IA générative viennent bouleverser.
Les collaborateurs se sont habitués à interagir avec des systèmes en langage naturel. Ils ne veulent plus chercher une information dans une arborescence complexe ou naviguer dans des centaines de champs techniques. Ils veulent poser une question simple et obtenir une réponse contextualisée. Cette évolution change profondément le rôle des catalogues de données.
Le catalogue ne peut plus être uniquement un référentiel documentaire. Il doit devenir un système capable de relier :
- et contexte opérationnel.
Le linéage devient ici un élément clé.
Pendant longtemps, le linéage a surtout été utilisé par les équipes techniques pour suivre les flux de transformation des données. Aujourd’hui, il prend une dimension métier beaucoup plus stratégique.
Un utilisateur doit pouvoir comprendre d’où vient une donnée, comment elle a été transformée, quels indicateurs l’utilisent, quelles règles métier lui sont associées, et quel niveau de confiance lui accorder. Sans cette compréhension, les usages IA restent fragiles.
Une IA peut générer une réponse rapidement. Mais si elle s’appuie sur des définitions contradictoires, des métadonnées incomplètes ou une documentation obsolète, elle accélère surtout la diffusion d’erreurs.
C’est pour cette raison que de nombreuses entreprises commencent à repositionner leurs projets de gouvernance non plus comme des projets de conformité, mais comme des fondations nécessaires à l’industrialisation de l’IA.
Comment rendre un catalogue de données réellement exploitable ?
Les entreprises qui réussissent leur gouvernance des données adoptent généralement une approche différente. Elles ne cherchent plus uniquement à documenter la donnée. Elles cherchent à simplifier son exploitation métier. Cela implique plusieurs évolutions importantes.
Relier automatiquement technique et métier
L’un des principaux freins actuels reste la séparation entre les métadonnées techniques et les définitions métier. Lorsque ces deux mondes restent isolés, les utilisateurs ne comprennent pas réellement ce qu’ils manipulent.
Les organisations les plus avancées cherchent désormais à créer des liens automatiques entre les tables techniques, les indicateurs métier, les documents associés, les règles de calcul et les usages opérationnels.
Réduire la dépendance aux experts
Un projet de gouvernance ne peut pas reposer durablement sur quelques personnes capables de “traduire” les données. L’objectif devient donc de capitaliser progressivement la connaissance métier dans des systèmes capables de la restituer simplement. Les agents IA ouvrent ici une nouvelle étape.
Ils permettent de transformer un catalogue statique en interface conversationnelle capable d’expliquer une donnée, de retrouver un indicateur, de contextualiser une définition ou d’orienter un utilisateur vers la bonne source d’information. Le catalogue devient alors beaucoup plus accessible pour les métiers.
Penser usage avant documentation
Beaucoup de projets échouent parce qu’ils démarrent par une logique exhaustive : documenter tout, classifier tout, gouverner tout. Cette approche produit souvent des projets longs, complexes et difficiles à maintenir .
Les démarches les plus efficaces commencent généralement par les usages prioritaires : reporting critique, indicateurs stratégiques, conformité, IA générative, support opérationnel ou onboarding métier. La gouvernance devient alors un levier de performance et non une contrainte documentaire.
Evolution du rôle du catalogue de données
Approche traditionnelle | Nouvelle approche augmentée par l’IA |
Documentation technique | Expérience conversationnelle |
Référentiel statique | Système vivant et contextualisé |
Utilisation par les experts | Exploitation par les métiers |
Recherche par mots-clés | Questions en langage naturel |
Gouvernance documentaire | Gouvernance orientée usage |
Vers une gouvernance des données réellement exploitable
Les entreprises ont longtemps considéré les catalogues de données comme des référentiels techniques. Avec l’IA générative, ils deviennent progressivement des systèmes d’accès à la connaissance. Cette évolution change profondément les attentes des métiers. Les utilisateurs ne veulent plus seulement documenter les données. Ils veulent comprendre, interroger et exploiter simplement le patrimoine informationnel de l’entreprise.
Chez JEMS, nous accompagnons les organisations dans cette transformation en concevant des systèmes capables de relier gouvernance, patrimoine documentaire et exploitation métier des données grâce à l’IA.
L’objectif n’est pas de remplacer les outils existants, mais de rendre enfin leur usage accessible, fiable et utile à grande échelle grâce à une nouvelle expérience conversationnelle autour des données et des connaissances métier.
Pour aller plus loin, découvrez également l’approche IA DataKnowledge développée par JEMS autour de l’exploitation intelligente des connaissances d’entreprise :