Les grands modèles de langage (LLMs) ouvrent des perspectives fascinantes, mais leur fiabilité reste un défi crucial. Chez JEMS, nous explorons des techniques pour limiter les risques liés aux « hallucinations », afin d’assurer des résultats pertinents et robustes dans des contextes critiques. Découvrez notre méthodologie et les solutions que nous privilégions.
Une faiblesse par construction
Les LLMs sont des machines statistiques. Elles prédisent et génèrent le prochain mot à émettre sur la base de la probabilité liée au contexte qu’on lui fournit, c’est-à-dire des mots précédents. Les résultats produits depuis 2022 sont sans l’ombre d’un doute spectaculaires, tout autant que les « ratés » qui sont parfois connus sous le nom « d’hallucinations ». Le fait qu’un mot soit « probable » ne signifie en rien qu’il soit « juste ».
Les risques des hallucinations
Si ces hallucinations peuvent se révéler « acceptables » dans le cadre d’un travail de création, d’imagination où elles peuvent permettre de considérer des aspects auxquels on ne penserait pas ; celles-ci peuvent se révéler désastreuses dans le cas où la qualité de la génération importe. Par exemple :
- Réponse à un client sur un point précis du contrat. Les histoires d’atteinte à l’image des sociétés se multiplient ;
- Fonctionnement d’un Agent ne prenant pas la bonne décision, n’invoquant pas le bon outil, ce qui peut nuire grandement à sa performance.
Les travaux
La technique la plus simple pour éviter ces désagréments est de mettre la « température » à zéro. Ce paramètre représente en fait la représentation statistique en sortie du réseau de neurone. Plus la « température » est élevée, plus les poids statistiques des mots candidats se rapprochent et donc plus texte peu prendre une direction ou une autre.
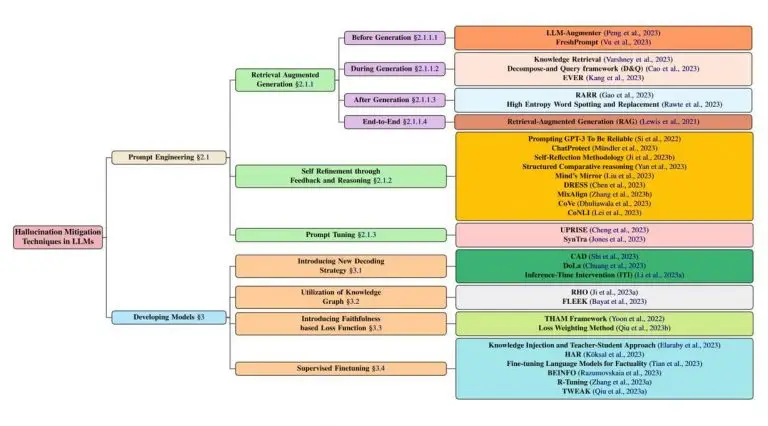
Malheureusement, jouer sur ce seul paramètre ne suffira pas et il conviendra de trouver d’autres solutions pour maitriser la production des LLMs. De nombreux articles scientifiques ont été rédigés à ce sujet et une synthèse est d’ailleurs disponible ici (https://arxiv.org/html/2401.01313v2). Les auteurs distinguent deux grandes catégories de méthodes :
- Les approches liées aux prompts, qui optimisent la formulation des questions posées au modèle.
- Les ajustements liés aux modèles, impliquant des modifications structurelles ou des entraînements spécifiques.
De notre point de vue, les méthodes liées aux modèles sont à la fois :
- Soumises aux mêmes risques.
Elles sont plus complexes, car nécessitent dans la plupart des cas une base d’entrainement. Que cela soit sous la forme classique de questions / réponses (souvent utilisé dans ces cas de fine tuning) ou bien en s’appuyant sur la structure même des modèles :
- Modification des probabilités de sortie (« Context-Aware-Decoding », « Decoding by Constrasting Layers »)
- Application de techniques « d’Attention » afin de conserver la génération focalisée sur les paramètres importants
Elles sont soumises aux mêmes risques, car in fine, il n’y a pas de contrôle de la génération, toujours statistique, en sortie.
Les autres techniques présentées dans l’étude évoquée, suivent une approche différente, focalisée sur la question et les informations fournies. Le LLM n’est pas remis en question ici, ce qui offre deux avantages :
- Les solutions proposées sont adaptables à tout type de LLM.
- Ne sont pas soumises à l’évolution des versions et mises à jour régulières des modèles qui nécessiteraient de prendre le travail précédent.
De fait, ces techniques s’appuient sur des solutions « sur étagères » et cherchent au contraire à « cadrer », « contrôler » la production d’un LLM, quitte à les reprendre.
Les techniques pour encadrer la production des LLMs
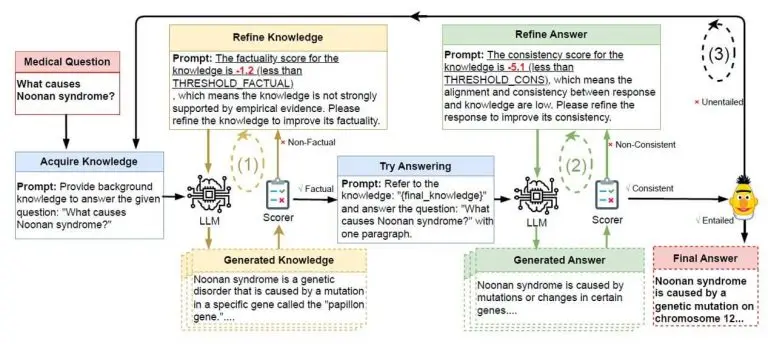
À la base, on retrouvera la mécanique de type « Guardrails ». Il s’agit là d’avoir une boucle de réaction (un peu à la manière des mécanismes d’asservissement) c’est-à-dire un mécanisme contrôlant la production par rapport aux attentes. Tant que la qualité n’atteint pas le niveau attendu, le LLM est invité à régénérer une nouvelle réponse.
Plusieurs méthodes désignées sous le nom de méthodes d’affinage par évaluation et raisonnement (self-refinement through feedback and reasoning) sont évoquées dans l’article. Citons notamment :
- Chat-Protect : cette méthode vise à mettre en évidence les contradictions et incohérences dans le raisonnement.
- Self-Reflection : Intégration progressive de données dans la réflexion
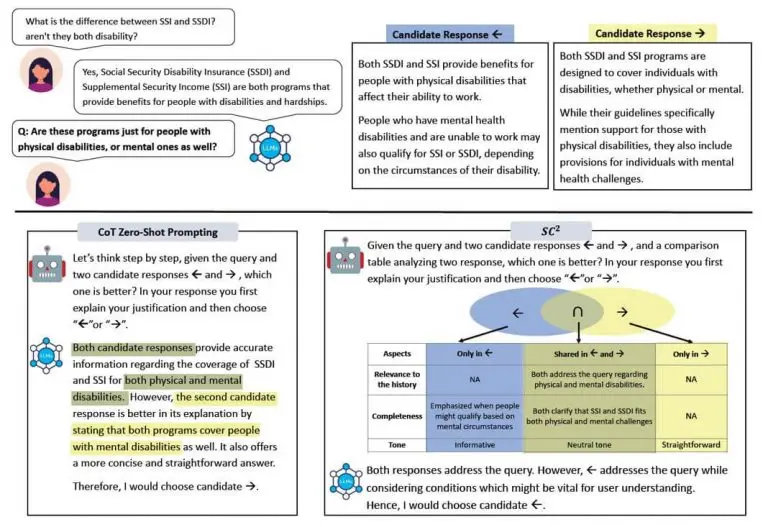
- Structured Comparative Reasoning : la méthode produit des résultats intermédiaires différents et cherche à conserver le résultat le plus pertinent. En fonctionnant par étapes, le résultat abouti à une meilleure cohérence et complétude.
Cette dernière méthode n’est d’ailleurs pas sans rappeler la « chaine de vérification » (Chain Of Verification – CoVe) qui vise à auto vérifier ses propres générations en générant des questions et en y répondant. De même, CoNLI (Chain of Natural Language Inference) en « auto critiquant » ses réponses par rapports aux informations fournies en amont.
De manière générale, on peut penser à des réflexives, c’est-à-dire poussant le LLM à vérifier ses propres réponses par rapports aux documents fournis et à la question posée. En tant qu’être humain, cela revient à lire ce qu’on écrit avant de l’envoyer !
Les méthodes basées sur les prompts ou la gestion des sorties présentent des avantages significatifs en termes de flexibilité, stabilité, ou encore simplicité par rapport aux ajustements directs des LLMs. Et ces approches nous permettent de proposer des solutions robustes, adaptables et accessibles, sans dépendre de la complexité technique des modèles eux-mêmes.
Conclusion
Les hallucinations font donc partie de risques inhérents aux LLMs. Si dans les domaines créatifs, ceci peut s’avérer une chance, il est malheureusement d’autres domaines dans lesquels ceci peut devenir inacceptable. Plusieurs techniques sont disponibles et du point de vue de JEMS, il est préférable de privilégier celles indépendantes des LLMs et visant la correction des erreurs plutôt qu’espérer un LLM « parfait ».
On notera cependant un point commun :
- Contrôler la production des LLMs en découpant une tâche par sous-tâches, petits pas.
Une hallucination, une divergence sera plus faible sur une courte distance qu’une longue
- À chaque étape, « auto-challenger » ce qui a été généré, si possible avec une approche de vérification par rapport à des faits avérés, mais dans tous les cas en prenant une approche contradictoire pour vérifier la pertinence de ce qui est produit.
Notre démarche repose sur l’idée que la maîtrise de l’IA passe par une approche structurée, intégrant des solutions adaptées à chaque contexte métier. En travaillant avec nos clients, nous développons des outils qui maximisent les opportunités offertes par l’IA tout en réduisant les incertitudes.
Et vous, comment encadrez-vous vos projets IA pour garantir des résultats fiables et pertinents ? Nos experts sont là pour vous accompagner dans cette transformation.